














はじめに
データ管理の分野において、組織の独自のニーズに応えるデータベースシステムを設計することは、多面的な課題です。このプロセスは、コンセプチュアル、ロジカル、物理の3つの明確な段階に分かれて進行します。これらの設計レベルは、データの本質を捉えるだけでなく、その整合性、効率性、セキュリティを確保する上で極めて重要です。本記事では、これらの3つのレベルをたどり、それぞれの意義や違い、そしてどのように統合されて堅牢なデータベースシステムが構築されるかを検証します。

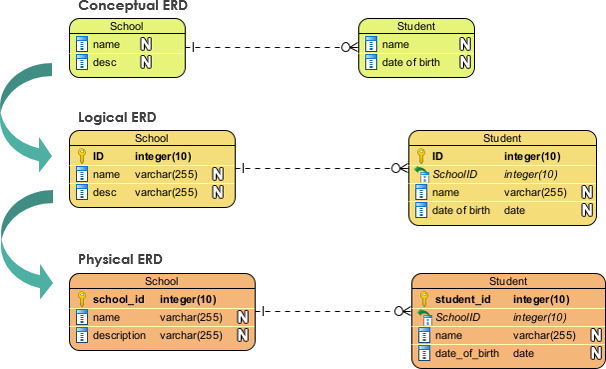
コンセプチュアル vs ロジカル vs 物理 ERD
データベースは現代の情報システムの基盤であり、整理された構造化されたデータの保管庫として機能します。データベースを設計する際には、コンセプチュアル、ロジカル、物理の3つの異なるレベルを含む構造的なアプローチを採用することが不可欠です。各レベルにはそれぞれ独自の目的があり、堅牢で効率的なデータベースシステムの構築において重要な役割を果たします。本記事では、これらの3つのレベルを検証し、それらの違いを深く掘り下げ、その意義を具体例で示します。
-
コンセプチュアルデータベース設計
コンセプチュアルデータベース設計は、データベース設計プロセスにおける最も高い抽象度のレベルです。この段階では、設計者は技術的な実装の詳細にこだわらず、問題領域を理解し、データベースの全体的な構造を定義することに注力します。主な目的は、データとその関係性を明確かつ包括的に表現することです。
問題の説明:大学が学生情報を管理するためのデータベースを作成したいと仮定します。コンセプチュアル設計段階での主な関心は、大学の文脈内での主要なエンティティとそれらの関係性を特定することです。主要なエンティティには、学生、授業、教員、部署などが含まれるでしょう。関係性としては、学生が授業に登録すること、教員が授業を担当すること、部署が授業を管理することなどが挙げられます。
例:
- エンティティ:学生、授業、教員、部署
- 関係性:学生が授業に登録する、教員が授業を担当する、部署が授業を管理する
-
ロジカルデータベース設計
ロジカルデータベース設計は、コンセプチュアルと物理の間のギャップを埋める役割を果たします。この段階では、設計者はコンセプチュアルモデルをより詳細な表現に翻訳し、データ構造、関係性、制約に注目します。ロジカル設計は特定のデータベース管理システム(DBMS)に依存せず、エンティティ関係図(ERD)や類似のモデリング手法で表現されることが一般的です。
問題の説明:大学の例を引き続き用いて、ロジカル設計段階では、各エンティティの属性を定義し、データ型、主キー、外部キーを明示します。この段階では、データの重複を排除し、データの整合性を確保するためにデータの正規化も行われます。
例:
- 学生エンティティ:
- 属性:StudentID(主キー)、FirstName、LastName、DateOfBirth
- 授業エンティティ:
- 属性:CourseID(主キー)、CourseName、Credits
- 教員エンティティ:
- 属性:InstructorID(主キー)、FirstName、LastName
- 部署エンティティ:
- 属性:DepartmentID(主キー)、DepartmentName
-
物理データベース設計
物理データベース設計は、データベース設計プロセスにおける最も詳細で技術的なレベルです。この段階では、設計者はロジカル設計を特定のDBMS上でどのように実装するかを決定します。インデックス作成、ストレージ、パフォーマンス最適化、セキュリティ対策などの点が検討されます。
問題の説明:大学のデータベースを例にすると、物理設計段階では、使用するDBMS(例:MySQL、Oracle、PostgreSQL)を決定し、実際のデータベーススキーマを作成します。これには、正確なテーブル構造、データ型、制約、インデックスの指定が含まれます。また、データのストレージ、パーティショニング、アクセス制御に関する決定も含まれます。
例:
- 学生テーブル (MySQL構文):
sql
CREATE TABLE 学生 (
StudentID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
DateOfBirth DATE
);
- コーステーブル:
sql
CREATE TABLE コース (
CourseID INT PRIMARY KEY,
CourseName VARCHAR(100),
Credits INT
);
違いの要約
以下の表は、データベース設計の3つのレベルが目的、焦点、特定のDBMSからの独立性、モデリングツール、および各レベルにおける属性、関係、キーの例の観点からどのように異なるかを明確に示しています。これらの違いを理解することは、効果的で効率的なデータベースシステムを構築するために不可欠です。
以下の表は、データベース設計の3つのレベル、すなわち概念設計、論理設計、物理設計の間の簡潔な対比を示しています。
| 側面 | 概念設計 | 論理設計 | 物理設計 |
|---|---|---|---|
| 抽象化レベル | 最高レベルの | 中間レベル | 最低レベルの |
| 抽象化 | 抽象化の | 抽象化 | |
| 目的 | 全体の構造、エンティティ、および | 概念設計を翻訳して | データベースを実装する |
| 構造、エンティティ、および | モデルを詳細なデータに変換する | 特定のDBMS上で、 | |
| 関係性 | 構造、属性、 | 指定を含む | |
| および制約 | ストレージと最適化 | ||
| 焦点 | データと関係性 | データ構造、 | 実装の詳細 |
| 高いレベルで | 属性、キー、および | インデックス作成など、 | |
| 関係性 | ストレージおよびセキュリティ | ||
| 独立性 | ~に依存しない | 特定のものに依存しない | DBMS固有のもので、 |
| 任意のDBMS | DBMS | ハードウェア | |
| モデリングツール | 高レベルの図、 | エンティティ関係 | SQL、データベース管理 |
| エンティティなどの | 図(ERD)、 | システム固有のツール | |
| 関係図 | 正規化技術 | およびユーティリティ | |
| データ型と | データには関与しない | データ型を定義する、 | データ型を指定する、 |
| 制約 | 型または制約 | 制約、および | 制約、および |
| 関係 | 関係 | ||
| 例: 属性 | 学生の名前 | 学生の生年月日 | 学生の生年月日 |
| (VARCHAR、DATE) | |||
| 例: 関係 | 学生は~に登録する | 学生は~に登録する | 学生は~に登録する |
| コース | コース | コース | |
| 例: キー | 該当なし | 学生ID(主キー) | 学生ID(主キー) |
| コースID(主キー) | コースID(プライマリキー) |
データベース設計の最適化:3段階の選択
ITシステムのデータベースを開発する際に、概念的、論理的、物理的という3段階のデータベース設計をすべて経るかどうかは、プロジェクトの複雑さや要件によって異なります。多くの場合、特に規模が小さくまたは複雑性の低いシステムでは、簡略化されたアプローチの方が効率的であることがわかります。以下に考慮すべき点を示します:
- プロジェクトの複雑さ:規模が小さく、中程度の複雑性を持つシステムでは、これらの設計段階を統合したり簡略化したりできる場合があります。単純なプロジェクトでは、詳細な概念設計を必要とせず、論理設計から物理的実装へと迅速に移行できるかもしれません。
- 開発スケジュール:アジャイルや迅速開発の環境では、高レベルの概念設計から始め、プロジェクトの進行に伴って段階的に進化させるのが一般的です。開発を開始する前にすべての詳細を確定する必要はありません。
- リソース制約:時間や予算、専門知識の制約があると、より簡略化されたアプローチを取る必要があります。規模の小さいプロジェクトやプロトタイプでは、詳細な設計フェーズよりもスピードを優先する傾向があります。
- データベースシステム:場合によっては、確立されたデータベースシステムやフレームワークを使用している場合、既存のテンプレートや構造を活用でき、包括的な論理的および物理的設計フェーズの必要性が低下します。
- 変更管理:プロジェクトの要件が頻繁に変化する、または初期段階で明確でない場合、要件の変化に応じて柔軟に適応できる設計を維持した方が効率的である可能性があります。
しかし、大規模でミッションクリティカルな、または複雑なデータベースシステムでは、3段階すべての設計を経るよう強く推奨されます。これらの段階は、データの正確性、整合性、セキュリティ、パフォーマンスを確保するのに役立ちます。包括的な概念設計は、ステークホルダーがデータモデルについて理解し、合意を形成するのに役立ちます。論理設計は重複を排除し、関係を明確にします。物理設計は、選択したデータベースシステムにおける最適なパフォーマンス、スケーラビリティ、セキュリティを確保します。
多くの現実世界のシナリオでは、ハイブリッドアプローチも効果的です。まず高レベルの概念設計から始め、問題領域を把握し、次に論理設計に進んでデータ構造や関係を明確化します。堅固な論理モデルが得られたら、選択したデータベースシステムに実装するための物理設計に進みます。
すべてのITシステムにおいて、必ずしも3段階すべてのデータベース設計を経る必要があるわけではありませんが、選択はプロジェクトの要件、複雑さ、制約に基づくべきです。効率性と徹底性のバランスを取った適切なアプローチが、成功したデータベース開発の鍵となります。
結論
概念的、論理的、物理的データベース設計は、堅牢で効率的なデータベースシステムを構築する上で不可欠な要素です。各段階はデータベース設計プロセスにおいて独自の役割を果たし、問題領域の高レベルな理解から始まり、技術的な実装詳細へと進んでいきます。この構造化されたアプローチを採用することで、組織はデータ管理のニーズを効果的かつ効率的に満たすデータベースを確保できます。
効果的なデータベースシステムの構築には、3段階のアプローチが必要です。まず概念設計段階では、問題領域の理解とエンティティおよび関係の特定に注力します。次に論理設計段階へ進み、デザイナーは概念モデルをより詳細な表現に変換し、属性、キー、関係を明確にします。最後に物理設計段階では、論理モデルを具体的なデータベーススキーマに変換し、データ型、ストレージ、セキュリティ対策に関する決定を行います。これらの3段階のデータベース設計を習得することで、組織はデータの力を活かし、データが整理され、アクセス可能で価値ある状態を維持できます。