














डेटाबेस डिजाइन की दुनिया में, अमूर्त अवधारणाओं को भौतिक संरचनाओं में बदलना फलनशील और कुशल डेटाबेस प्रणालियों के निर्माण की एक महत्वपूर्ण चरण है। एंटिटी-रिलेशनशिप डायग्राम (ERD) से वास्तविक डेटाबेस स्कीमा, जिसमें SQL टेबल निर्माण भी शामिल है, में बदलाव की प्रक्रिया डेटाबेस विकास चक्र की एक मौलिक प्रक्रिया है। इस लेख में, हम देखेंगे कि ERD डेटा के अवधारणात्मक निर्माण और उसके डेटाबेस में व्यावहारिक कार्यान्वयन के बीच एक पुल के रूप में कैसे काम करते हैं।
ERD को समझना
डेटाबेस कार्यान्वयन के जटिलताओं में उतरने से पहले, ERD के उद्देश्य और घटकों को समझना आवश्यक है। एंटिटी-रिलेशनशिप डायग्राम डेटा मॉडल का दृश्य प्रतिनिधित्व है, जो एंटिटी, उनके गुण और उनके बीच संबंधों को दर्शाता है। ERD डेटाबेस संरचना के डिजाइन के लिए एक नक्शा के रूप में काम करता है, जो डेटाबेस विकासकर्ताओं, प्रबंधकों और हितधारकों को डेटा संगठन को दृश्य रूप से देखने और योजना बनाने में सहायता करता है।
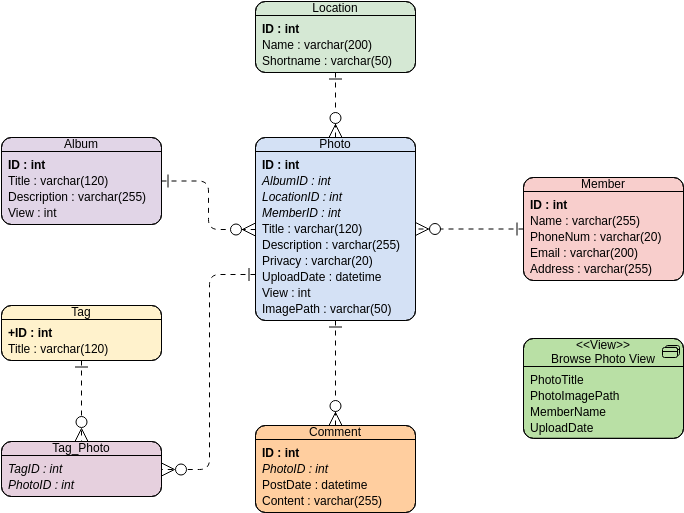
ERD के घटक
- एंटिटी: ये वे वस्तुएँ या अवधारणाएँ हैं जो डेटाबेस में प्रतिनिधित्व की जाती हैं, जो आमतौर पर ग्राहकों, उत्पादों या कर्मचारियों जैसी वास्तविक दुनिया की वस्तुओं से मेल खाती हैं। एंटिटी को ERD में आयताकार रूप में दर्शाया जाता है।
- गुण: गुण एंटिटी की विशेषताओं या गुणों को परिभाषित करते हैं। उदाहरण के लिए, “ग्राहक” एंटिटी के लिए गुणों में “ग्राहकआईडी,” “नाम,” “अंतिम नाम,” और “ईमेल” शामिल हो सकते हैं। गुणों को आमतौर पर ERD में गोलाकार रूप में दर्शाया जाता है, जो उनके संबंधित एंटिटी से जुड़े होते हैं।
- संबंध: संबंध बताते हैं कि एंटिटी कैसे एक दूसरे से जुड़ी हैं या एक दूसरे से संबंधित हैं। वे एंटिटी के बीच निर्भरता को स्पष्ट करते हैं और एक-एक, एक-बहुत या बहुत-बहुत संबंध हो सकते हैं। एंटिटी के बीच संबंध रेखाएँ इन संबंधों को निर्दिष्ट करती हैं, और वे आमतौर पर कार्डिनैलिटी संकेतकों के साथ आती हैं, जो संबंधित एंटिटी की अनुमत राशि को दर्शाते हैं।
ERD को डेटाबेस स्कीमा में बदलना
ERD से वास्तविक डेटाबेस स्कीमा में जाने की प्रक्रिया कई महत्वपूर्ण चरणों को शामिल करती है:
1. एंटिटी से टेबल मैपिंग
ERD में एंटिटी को डेटाबेस टेबल में बदला जाता है। प्रत्येक एंटिटी के भीतर एक गुण उसके संबंधित टेबल में एक कॉलम बन जाता है। उदाहरण के लिए, यदि हमारे पास “ग्राहक” एंटिटी है जिसमें “ग्राहकआईडी,” “नाम,” “अंतिम नाम,” और “ईमेल” गुण हैं, तो हम “ग्राहक” टेबल बनाएंगे जिसमें इन सभी गुणों के लिए कॉलम होंगे।
2. संबंध कार्यान्वयन
ERD में एंटिटी के बीच संबंधों को SQL में विभिन्न तरीकों से लागू किया जाता है:
- एक-एक संबंध: इस मामले में, एक एंटिटी का प्राथमिक कुंजी दूसरी एंटिटी के टेबल में विदेशी कुंजी बन जाता है।
- एक-बहुत संबंध: संबंध के “एक” तरफ के टेबल में एक विदेशी कुंजी होती है जो “बहुत” तरफ के टेबल के प्राथमिक कुंजी को संदर्भित करती है।
- बहुत-बहुत संबंध: आमतौर पर, इसे जंक्शन टेबल या सहसंबंधित एंटिटी के उपयोग से लागू किया जाता है, जिसमें संबंध में शामिल टेबलों को संदर्भित करने वाली विदेशी कुंजियाँ होती हैं।
3. कुंजी सीमाएँ और डेटा प्रकार
डेटाबेस टेबल के प्रत्येक कॉलम के लिए डेटा प्रकार निर्दिष्ट किए जाते हैं ताकि यह निर्धारित किया जा सके कि किस प्रकार के डेटा को संग्रहीत किया जा सकता है। साथ ही, प्राथमिक कुंजी और विदेशी कुंजी जैसी कुंजी सीमाएँ निर्धारित की जाती हैं ताकि डेटा अखंडता और टेबल के बीच संबंधों को बनाए रखा जा सके।
4. इंडेक्सिंग
प्रश्न प्रदर्शन में सुधार करने के लिए, खोज शर्तों में अक्सर उपयोग किए जाने वाले कॉलम पर इंडेक्स बनाए जाते हैं। इंडेक्स डेटा तक पहुँचने के लिए तेज़ तरीका प्रदान करते हैं।
5. डेटा अखंडता नियम
डेटाबेस डिजाइनर नियमों के माध्यम से डेटा अखंडता को बनाए रखते हैं। उदाहरण के लिए, “NOT NULL” नियम सुनिश्चित करते हैं कि एक कॉलम में NULL मान नहीं हो सकते हैं, जबकि “UNIQUE” नियम सुनिश्चित करते हैं कि कॉलम में मान अद्वितीय हों।
SQL टेबल निर्माण उदाहरण
आइए इस प्रक्रिया को एक सरल उदाहरण के साथ समझाएं:
मान लीजिए कि हमारे पास एक लाइब्रेरी सिस्टम का एरडी है, जिसमें “Book” और “Author” नामक एकताएं हैं, जो बहु-से-बहु संबंध “Author Wrote Book” द्वारा जुड़ी हैं। यहां हम इसे SQL टेबल निर्माण में कैसे बदलेंगे, उसका विवरण है:
- पुस्तक विशेषताओं (जैसे BookID, Title, PublicationYear) के लिए कॉलम वाली “Books” टेबल बनाएं।
- लेखक विशेषताओं (जैसे AuthorID, FirstName, LastName) के लिए कॉलम वाली “Authors” टेबल बनाएं।
- बहु-से-बहु संबंध का प्रतिनिधित्व करने के लिए “AuthorBook” टेबल बनाएं। इस टेबल में आमतौर पर दो कॉलम होते हैं, “AuthorID” और “BookID”, जो क्रमशः “Authors” और “Books” टेबल के लिए विदेशी कुंजियां के रूप में कार्य करते हैं।
इन चरणों का पालन करके, हमने एरडी को आवश्यक टेबल, संबंधों और प्रतिबंधों वाले वास्तविक डेटाबेस स्कीमा में सफलतापूर्वक बदल दिया है।
एरडी पर एक केस स्टडी: ऑनलाइन बुकस्टोर
कल्पना कीजिए कि आपको एक ऑनलाइन बुकस्टोर के लिए डेटाबेस डिजाइन करने का कार्य सौंपा गया है। सिस्टम को ग्राहकों को पुस्तकों के ब्राउज़ करने, खरीदारी करने और अपने खातों का प्रबंधन करने की अनुमति देनी चाहिए। लेखक और प्रकाशक भी पुस्तकों को जोड़ने और प्रबंधित करने के लिए खाते रखेंगे, जबकि प्रशासक पूरे सिस्टम के नियंत्रण में रहेंगे।
चरण 1: एंटिटी की पहचान करें
एरडी मॉडलिंग का पहला चरण सिस्टम से संबंधित एंटिटी की पहचान करना है। इस मामले में, हम निम्नलिखित एंटिटी की पहचान कर सकते हैं:
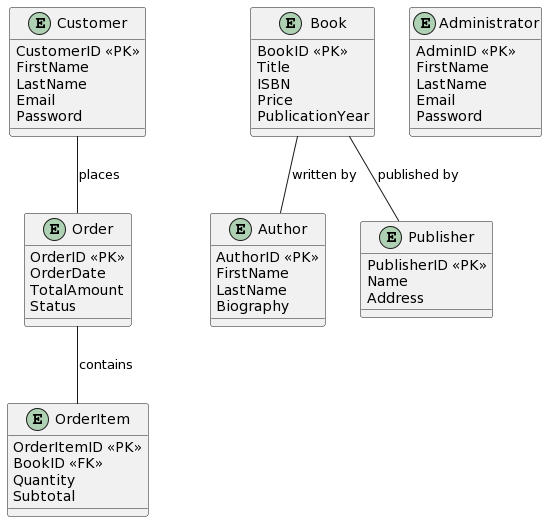
- ग्राहक: उन व्यक्तियों का प्रतिनिधित्व करता है जो ऑनलाइन बुकस्टोर का उपयोग करते हैं। विशेषताएं में CustomerID, FirstName, LastName, Email और Password शामिल हो सकते हैं।
- पुस्तक: खरीदारी के लिए उपलब्ध पुस्तकों का प्रतिनिधित्व करता है। विशेषताएं में BookID, Title, Author(s), ISBN, Price और PublicationYear शामिल हो सकते हैं।
- लेखक: पुस्तकों के लेखकों का प्रतिनिधित्व करता है। विशेषताएं में AuthorID, FirstName, LastName और Biography शामिल हो सकते हैं।
- प्रकाशक: पुस्तकों के प्रकाशकों का प्रतिनिधित्व करता है। विशेषताएं में PublisherID, Name और Address शामिल हो सकते हैं।
- आदेश: ग्राहक आदेशों का प्रतिनिधित्व करता है। विशेषताएं में OrderID, OrderDate, TotalAmount और Status शामिल हो सकते हैं।
- आदेश आइटम: आदेश के भीतर व्यक्तिगत आइटम का प्रतिनिधित्व करता है। विशेषताएं में OrderItemID, BookID, Quantity और Subtotal शामिल हो सकते हैं।
- प्रशासक: सिस्टम प्रशासकों का प्रतिनिधित्व करता है। विशेषताएं में AdminID, FirstName, LastName, Email और Password शामिल हो सकते हैं।
चरण 2: संबंधों को परिभाषित करें
अगला, हम यह तय करते हैं कि इन एंटिटी कैसे एक-दूसरे से संबंधित हैं:
- एक ग्राहक बहुत सारे आदेश (एक से बहुत अनुसंधान संबंध).
- एक आदेश में कई को शामिल कर सकता हैआदेश आइटम (एक से बहुत अनुसंधान संबंध).
- एक पुस्तक कई द्वारा लिखी जा सकती हैलेखक, और एक लेखक कई लिख सकते हैंपुस्तकें (बहुत से बहुत अनुसंधान संबंध).
- एक पुस्तक केवल एक के साथ हो सकती हैप्रकाशक, लेकिन एक प्रकाशक कई प्रकाशित कर सकते हैंपुस्तकें (बहुत से एक अनुसंधान संबंध).
- एक प्रशासक पूरे प्रणाली के अधिकारी है लेकिन इस सरलीकृत मॉडल में अन्य एकाधिकारों से सीधे संबंधित नहीं है।
चरण 3: ईआरडी बनाएं
अब, हम इन एकाधिकारों और उनके संबंधों को दृश्य रूप से प्रदर्शित करने के लिए ईआरडी बनाते हैं। हमारी ऑनलाइन पुस्तकालय के लिए ईआरडी का सरलीकृत संस्करण यहां दिया गया है:
चरण 4: गुणों को परिभाषित करें
ERD में प्रत्येक संघटक के लिए, हम उसके गुणों को परिभाषित करते हैं। उदाहरण के लिए:
- ग्राहक: ग्राहकID (मुख्य कुंजी), प्रथम नाम, अंतिम नाम, ईमेल, पासवर्ड।
- पुस्तक: पुस्तकID (मुख्य कुंजी), शीर्षक, ISBN, मूल्य, प्रकाशन वर्ष।
- लेखक: लेखकID (मुख्य कुंजी), प्रथम नाम, अंतिम नाम, जीवनी।
- प्रकाशक: प्रकाशकID (मुख्य कुंजी), नाम, पता।
- आदेश: आदेशID (मुख्य कुंजी), आदेश तिथि, कुल राशि, स्थिति।
- आदेश वस्तु: आदेश वस्तुID (मुख्य कुंजी), पुस्तकID (विदेशी कुंजी), मात्रा, उपकुल।
चरण 5: डेटाबेस को सामान्यीकृत करें (वैकल्पिक)
सामान्यीकरण डेटाबेस में डेटा को व्यवस्थित करने की प्रक्रिया है ताकि अतिरिक्तता कम की जा सके और डेटा अखंडता में सुधार किया जा सके। आपकी प्रणाली की जटिलता के आधार पर, आपको तालिकाओं पर सामान्यीकरण नियमों को लागू करने की आवश्यकता हो सकती है।
चरण 6: डेटाबेस कार्यान्वयन
अंत में, ERD वास्तविक डेटाबेस तालिकाओं के निर्माण, संबंधों, सीमाओं और डेटा प्रकारों को परिभाषित करने के लिए एक मार्गदर्शिका के रूप में कार्य करता है, जिसमें SQL या डेटाबेस प्रबंधन उपकरण का उपयोग किया जाता है। इस चरण में ERD को तालिका निर्माण के लिए SQL बयानों में अनुवाद करना शामिल होता है।
इस अध्ययन में, हमने ऑनलाइन पुस्तकालय के लिए ERD मॉडलिंग की प्रक्रिया को चित्रित किया है। ERD प्रभावी डेटाबेस प्रणालियों के डिजाइन में महत्वपूर्ण भूमिका निभाते हैं, यह सुनिश्चित करते हुए कि डेटा तार्किक ढंग से व्यवस्थित हो, और संबंधों को ऐसे परिभाषित किया जाए कि एप्लिकेशन की कार्यक्षमता का समर्थन किया जा सके।
निष्कर्ष
एंटिटी-रिलेशनशिप आरेख (ERD) डेटाबेस संरचनाओं के डिजाइन और दृश्यीकरण के लिए अमूल्य उपकरण हैं। वे डेटाबेस कार्यान्वयन के लिए एक नक्शा के रूप में कार्य करते हैं, जो अमूल्य अवधारणाओं को वास्तविक डेटाबेस स्कीमा में बदलने के लिए मार्गदर्शन करते हैं। एंटिटी के तालिकाओं के साथ मैपिंग, संबंधों के निर्माण और डेटा प्रकारों और सीमाओं को परिभाषित करके, ERD डेटा मॉडलिंग और वास्तविक डेटाबेस प्रणालियों के बीच के अंतर को दूर करते हैं। यह प्रक्रिया जटिल होने के बावजूद, संगठनों और एप्लिकेशन की आवश्यकताओं को पूरा करने वाले विश्वसनीय और कुशल डेटाबेस बनाने के लिए आवश्यक है।