












In der Welt der Datenbankgestaltung ist die Umsetzung abstrakter Konzepte in greifbare Strukturen ein entscheidender Schritt, um funktionale und effiziente Datenbanksysteme zu entwickeln. Dieser Übergang von Entity-Relationship-Diagrammen (ERDs) zu tatsächlichen Datenbankschemata, einschließlich der Erstellung von SQL-Tabellen, ist ein grundlegender Prozess im Lebenszyklus der Datenbankentwicklung. In diesem Artikel werden wir untersuchen, wie ERDs als Brücke zwischen der Konzeption von Daten und ihrer praktischen Umsetzung innerhalb einer Datenbank dienen.
Verständnis des ERD
Bevor man sich mit den Feinheiten der Datenbankimplementierung beschäftigt, ist es unerlässlich, den Zweck und die Bestandteile eines ERDs zu verstehen. Ein Entity-Relationship-Diagramm ist eine visuelle Darstellung des Datenmodells, das die Entitäten, ihre Attribute und die Beziehungen zwischen ihnen erfasst. Der ERD dient als Bauplan für die Gestaltung der Datenbankstruktur und hilft Datenbankentwicklern, Administratoren und Stakeholdern, die Datenorganisation effektiv zu visualisieren und zu planen.
Bestandteile eines ERD
- Entitäten: Dies sind Objekte oder Konzepte, die innerhalb der Datenbank dargestellt werden, die oft realen Entitäten wie Kunden, Produkten oder Mitarbeitern entsprechen. Entitäten werden in einem ERD als Rechtecke dargestellt.
- Attribute: Attribute definieren die Eigenschaften oder Merkmale von Entitäten. Beispielsweise könnten für eine „Kunde“-Entität die Attribute „KundenID“, „Vorname“, „Nachname“ und „E-Mail“ sein. Attribute werden in einem ERD typischerweise als Ovale dargestellt, die mit ihren jeweiligen Entitäten verbunden sind.
- Beziehungen: Beziehungen zeigen an, wie Entitäten miteinander verbunden oder verknüpft sind. Sie klären Abhängigkeiten zwischen Entitäten und können ein-zu-eins, ein-zu-viele oder viele-zu-viele sein. Beziehungslinien zwischen Entitäten spezifizieren diese Verbindungen und werden oft durch Kardinalitätsangaben ergänzt, die die zulässige Anzahl an verbundenen Entitäten anzeigen.
Übersetzung von ERDs in Datenbankschemata
Der Prozess des Übergangs von ERDs zu tatsächlichen Datenbankschemata umfasst mehrere entscheidende Schritte:
1. Entität-zu-Tabelle-Zuordnung
Entitäten im ERD werden in Datenbanktabellen umgewandelt. Jedes Attribut innerhalb einer Entität wird zu einer Spalte in der entsprechenden Tabelle. Wenn wir beispielsweise eine „Kunde“-Entität mit den Attributen „KundenID“, „Vorname“, „Nachname“ und „E-Mail“ haben, erstellen wir eine „Kunden“-Tabelle mit Spalten für jedes dieser Attribute.
2. Umsetzung von Beziehungen
Beziehungen zwischen Entitäten im ERD werden durch verschiedene Mechanismen in SQL umgesetzt:
- Ein-zu-eins-Beziehung: In diesem Fall wird der Primärschlüssel einer Entität zum Fremdschlüssel in der Tabelle der anderen Entität.
- Ein-zu-viele-Beziehung: Die Tabelle auf der „einen“ Seite der Beziehung enthält einen Fremdschlüssel, der auf den Primärschlüssel der Tabelle auf der „vielen“ Seite verweist.
- Viele-zu-viele-Beziehung: Typischerweise wird dies durch eine Verbindungstabelle oder assoziative Entität umgesetzt, die Fremdschlüssel enthält, die auf die Tabellen verweisen, die an der Beziehung beteiligt sind.
3. Schlüsselbeschränkungen und Datentypen
Für jede Spalte in der Datenbanktabelle werden Datentypen angegeben, um festzulegen, welche Art von Daten gespeichert werden kann. Zudem werden Schlüsselbeschränkungen wie Primärschlüssel und Fremdschlüssel definiert, um die Datenintegrität und die Beziehungen zwischen Tabellen zu gewährleisten.
4. Indizierung
Um die Abfrageleistung zu verbessern, werden Indizes auf Spalten erstellt, die häufig in Suchbedingungen verwendet werden. Indizes bieten eine schnellere Möglichkeit, auf Daten zuzugreifen.
5. Regeln zur Datenintegrität
Datenbankdesigner setzen die Datenintegrität durch Beschränkungen durch. Zum Beispiel stellen „NOT NULL“-Beschränkungen sicher, dass eine Spalte keine NULL-Werte enthalten kann, während „UNIQUE“-Beschränkungen gewährleisten, dass die Werte in einer Spalte eindeutig sind.
Beispiel zur Erstellung einer SQL-Tabelle
Lassen Sie uns diesen Prozess anhand eines einfachen Beispiels veranschaulichen:
Angenommen, wir haben ein ERD, das ein Bibliothekssystem mit den Entitäten „Buch“ und „Autor“ darstellt, die durch eine Many-to-Many-Beziehung „Autor hat Buch geschrieben“ verbunden sind. Hier ist, wie wir dies in die Erstellung von SQL-Tabellen übersetzen würden:
- Erstellen Sie eine „Bücher“-Tabelle mit Spalten für Buchattribute (z. B. BuchID, Titel, Erscheinungsjahr).
- Erstellen Sie eine „Autoren“-Tabelle mit Autoren-Attributen (z. B. AutorID, Vorname, Nachname).
- Erstellen Sie eine „AutorBuch“-Tabelle, um die Many-to-Many-Beziehung darzustellen. Diese Tabelle enthält typischerweise zwei Spalten, „AutorID“ und „BuchID“, die jeweils als Fremdschlüssel auf die Tabellen „Autoren“ und „Bücher“ verweisen.
Durch die Einhaltung dieser Schritte haben wir das ERD erfolgreich in ein tatsächliches Datenbankschema mit den erforderlichen Tabellen, Beziehungen und Einschränkungen übersetzt.
Ein Fallstudie zum ERD: Online-Buchhandlung
Stellen Sie sich vor, Sie müssten die Datenbank für einen Online-Buchhandel entwerfen. Das System sollte Kunden das Durchstöbern von Büchern, das Kauf von Büchern und die Verwaltung ihrer Konten ermöglichen. Autoren und Verlage werden ebenfalls Konten haben, um Bücher hinzuzufügen und zu verwalten, während Administratoren das gesamte System überwachen werden.
Schritt 1: Entitäten identifizieren
Der erste Schritt beim ERD-Modellieren besteht darin, die für das System relevanten Entitäten zu identifizieren. In diesem Fall können wir die folgenden Entitäten identifizieren:
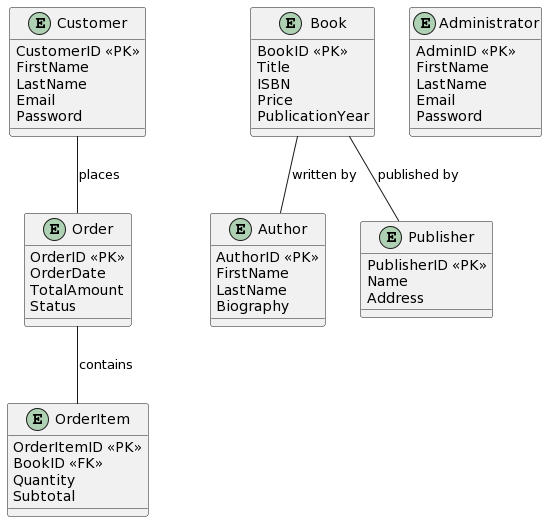
- Kunde: Stellt die Personen dar, die den Online-Buchhandel nutzen. Attribute könnten CustomerID, Vorname, Nachname, E-Mail und Passwort umfassen.
- Buch: Stellt die zum Kauf verfügbaren Bücher dar. Attribute könnten BuchID, Titel, Autor(en), ISBN, Preis und Erscheinungsjahr umfassen.
- Autor: Stellt die Autoren der Bücher dar. Attribute könnten AutorID, Vorname, Nachname und Biografie umfassen.
- Verlag: Stellt die Verlage der Bücher dar. Attribute könnten VerlagID, Name und Adresse umfassen.
- Bestellung: Stellt Kundenbestellungen dar. Attribute könnten Bestell-ID, Bestelldatum, Gesamtbetrag und Status umfassen.
- Bestellposition: Stellt einzelne Artikel innerhalb einer Bestellung dar. Attribute könnten Bestellpositions-ID, BuchID, Menge und Teilbetrag umfassen.
- Administrator: Stellt Systemadministratoren dar. Attribute könnten Admin-ID, Vorname, Nachname, E-Mail und Passwort umfassen.
Schritt 2: Beziehungen definieren
Als Nächstes bestimmen wir, wie diese Entitäten miteinander verbunden sind:
- Ein Kunde kann mehrere Bestellungen (Beziehung von einem zu vielen).
- Ein Bestellung kann mehrere Bestellpositionen (Beziehung von einem zu vielen).
- Ein Buch kann von mehreren Autoren, und ein Autor kann mehrere Bücher (Beziehung von vielen zu vielen).
- Ein Buch kann nur einen Verlag, aber ein Verlag kann mehrere Bücher (Beziehung von vielen zu einem).
- Ein Administrator überwacht das gesamte System, ist aber in diesem vereinfachten Modell nicht direkt mit anderen Entitäten verbunden.
Schritt 3: Erstellen des ERD
Nun erstellen wir das ERD, um diese Entitäten und ihre Beziehungen visuell darzustellen. Hier ist eine vereinfachte Version des ERD für unseren Online-Buchhandel:
Schritt 4: Attribute definieren
Für jedes Entität im ERD definieren wir ihre Attribute. Zum Beispiel:
- Kunde: KundenID (Primärschlüssel), Vorname, Nachname, E-Mail, Passwort.
- Buch: BuchID (Primärschlüssel), Titel, ISBN, Preis, Erscheinungsjahr.
- Autor: AutorenID (Primärschlüssel), Vorname, Nachname, Biografie.
- Verlag: VerlagsID (Primärschlüssel), Name, Adresse.
- Bestellung: BestellungsID (Primärschlüssel), Bestelldatum, Gesamtbetrag, Status.
- Bestellposition: BestellpositionsID (Primärschlüssel), BuchID (Fremdschlüssel), Menge, Teilbetrag.
Schritt 5: Datenbank normalisieren (optional)
Die Normalisierung ist der Prozess der Organisation von Daten in einer Datenbank, um Redundanz zu reduzieren und die Datenintegrität zu verbessern. Je nach Komplexität Ihres Systems müssen Sie möglicherweise Normalisierungsregeln auf die Tabellen anwenden.
Schritt 6: Datenbank implementieren
Schließlich dient das ERD als Leitfaden zum Erstellen der tatsächlichen Datenbanktabellen, zur Definition von Beziehungen, Einschränkungen und Datentypen mithilfe von SQL oder eines Datenbankverwaltungswerkzeugs. Dieser Schritt beinhaltet die Umsetzung des ERD in SQL-Anweisungen zum Tabellenanlegen.
In diesem Fallstudie haben wir den Prozess der ERD-Modellierung für einen Online-Buchhandel veranschaulicht. ERDs spielen eine entscheidende Rolle bei der Gestaltung effektiver Datenbanksysteme, indem sie sicherstellen, dass Daten logisch organisiert sind und Beziehungen klar definiert sind, um die Funktionalität der Anwendung zu unterstützen.
Fazit
Entität-Beziehung-Diagramme (ERDs) sind unverzichtbare Werkzeuge für die Gestaltung und Visualisierung von Datenbanksystemen. Sie dienen als Bauplan für die Datenbankimplementierung und leiten die Umsetzung abstrakter Konzepte in konkrete Datenbankschemata. Durch die Abbildung von Entitäten auf Tabellen, die Erstellung von Beziehungen sowie die Definition von Datentypen und Einschränkungen schließen ERDs die Lücke zwischen Datenmodellierung und realen Datenbanksystemen. Dieser Prozess, obwohl komplex, ist entscheidend für die Entwicklung robuster und effizienter Datenbanken, die die Anforderungen von Organisationen und Anwendungen erfüllen.